How To Crack Captchas
This page will teach you how to write a not-necessarily-very-good programme to beat some common captchas, but it will not provide any useful code to do so for you. It should give you an idea how to go about defeating captchas not listed here. But mostly, I hope it will be instructive for anyone who wants to write a less easily defeated captcha in the future, since apparently you’re all hopeless at it at the moment.
As everyone in the world knows by now, most websites and forums use “captchas” to try and stop computer programmes from posting fake comments containing adverts. “Captcha” stands for “Completely Automated Public Turing test to tell Computers and Humans Apart”. And as everyone in the world ought to have realised by now, they don’t work.
There exist a number of ways around them, the most cunning and most effective, although the most difficult to set up, is to build a pornographic website and get real humans to solve the captchas for you in exchange for naked pictures.
But mostly, they’re easy to get around because they’re shit. This, for example, is the default captcha that comes with the now obsolete phpbb2:

That is very easy to solve. (It should perhaps be pointed out at this stage that my job is in large part to extract shy information from images.) As with all the algorithms I’ll show you, this is the first and simplest one I could come up with, and it’s only the start. In all cases I will extract a binary mask of the letters for transferal to a more general OCR system. Also in all cases, I will use Matlab 6 to perform the analysis.
Here is the code required to make this captcha machine readable:
function bank=solvefuzzy(bank) [x y c n]=size(bank); %First, greyscale the lot by taking the red channel bank=bank(:,:,1,:); %Now blur it slightly. for (i=1:n) bank(:,:,1,i)=filter2(ones([3 3])/9, bank(:,:,1,i)); end %Now threshold it. bank=(bank<0.63); %Now trim the borders. bank(1:x,[1 y],:,:)=0; bank([1 x],1:y,:,:)=0;
Here is the result of this algorithm on four example captchas:

Now that wasn’t hard. And I know that the letter shapes aren’t ideal, but it’s a very uniform font they use, and the letters aren’t rotated, so it’s as easy as pie to extract the characters from this mask.
Of course, cracking obsolete captchas isn’t terribly useful, or wouldn’t be if anyone bothered to update their forums, so here’s a captcha from phpbb3:
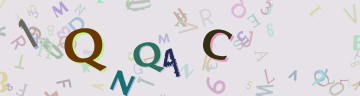
The first thing you should notice about this is that it’s gorgeous. But let’s have a look at the code required to break it:
function bank=solveclassy(bank) %First, greyscale the whole thing bank=mean(bank,3); %Now threshold it. bank=(bank<0.55);
That’s two commands. Now, let’s check the results.

So that’s done it perfectly, with no real image processing at all. Of course, this is a little unfair to the new captcha – it is in reality much tougher than phpbb2’s, because it uses many fonts and angles and sizes. So some kind of cunning would be required to turn these shapes back into characters, but that’s really nothing OCR software doesn’t do as a matter of course. And if you were to take each character individually (even if they overlap, the colours in the original image would distinguish them) and perform, say, a Radon transform on them about their centroids, this would give you a distinctive pattern for each letter and number in each font. The point is that from here it is entirely possibly to crack this captcha. Besides which, phpbb is open source, so training the process by Radon transforming all possible characters would be fairly simple.
But phpbb3 has another trick up its sleeve: a second type of captcha. This is the one used on www.phpbb3.com’s forum, so presumably they trust it:
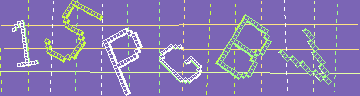
Aside from the fact that it looks like something from a bad Spectrum game, the first thing you should notice about this is that it has clearly been designed to be almost impossible to crack, by someone who knows nothing about cracking captchas. For example, the uniform background colour. Well over 90% of the image is a single colour and every pixel of every letter is that colour. Then, the individual letters are outlined in distinct and uniform colours, and then, as if that wasn’t helpful enough for crackers, the characters are made up of little square elements (which I will call ‘charels’), so we can reconstruct the characters down to the pixel, generally the right way up. It really couldn’t be more helpful if it tried.
So let’s see some code.
function result=solvefunky(bank); [x y c n]=size(bank); result=zeros([x,y,1,n]); %First, determine that background colours. %We assume the first colour with five continuous pixels of itself %along the first row is background. background=zeros(3,n); for (i=1:n) colour=[0 0 0]; j=1; count=0; while (count<5) if ((bank(1, j, 1, i)==colour(1)) && ... (bank(1, j, 2, i)==colour(2)) && ... (bank(1, j, 3, i)==colour(3))) count=count+1; else colour(:)=bank(1,y,:,i); end end background(:,i)=colour(:); %Next, find areas that are that colour backgroundareas(:,:,i)=((bank(:,:,1,i)==background(1,i)) & ... (bank(:,:,2,i)==background(2,i)) & ... (bank(:,:,3,i)==background(3,i))); %Now, find areas of that colour smaller than 15 pixels temp=bwlabel(backgroundareas(:,:,i), 4); small=zeros([x,y]); numberofregions=max(temp(:)); for (region=1:numberofregions) pixels=sum(temp(:)==region); if (pixels<15) thisarea=temp==region; %This leaves a lot of bits which aren'treal, but we know from %looking at the captcha that the letters are outlined in just %one colour, so lets eliminate anything that's got more than %one colour adjacent to it. (In fact, we allow one pixel of a %different colour as this works better.) adjacentpixels=(imdilate(thisarea, [0 1 0;1 1 1;0 1 0])&~thisarea); red=bank(:,:,1,i); green=bank(:,:,2,i); blue=bank(:,:,3,i); ar=red(adjacentpixels); ag=green(adjacentpixels); ab=blue(adjacentpixels); if ((sum((ar~=ar(1)))<2) && ... (sum((ag~=ag(1)))<2) && ... (sum((ab~=ab(1)))<2)) small=small|thisarea; end end end result(:,:,1,i)=small(:,:); end
That results in this rather pleasing image:
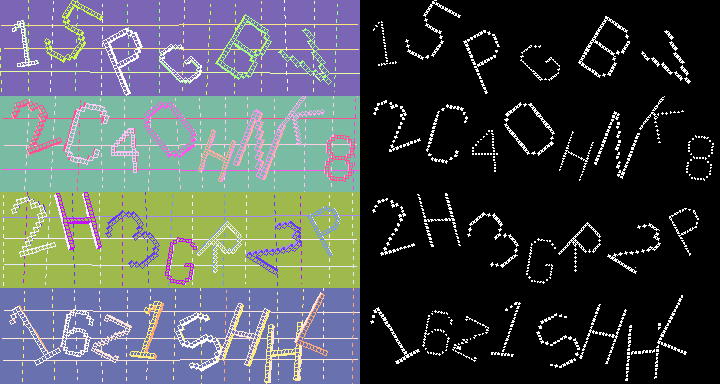
Now all I’ve done here is to find the pixels that are part of the larger “charels” which comprise the message. There’s still a lot of work to be done to find the message in ASCII format, but it can be done: you can separate the individual characters by recourse to the original image – each one is outlined in a distinctive colour, and if a colour is reused then it probably isn’t reused in adjacent characters, so a simple contiguity test will catch it; you can reorient and rescale each character by picking a charel arbitrarily and seeing where its neighbours lie relative to it, using the provided coloured outline as a guide and the ‘shadow’ colour to define the vertical and/or horizontal axes – this will allow you to build up a reoriented image of each letter, which can be easily checked against the known font to see which it most closely matches.
Those of you who know me should already have worked out that this took me less than one evening, including grabbing all the pictures and writing this entry. I wouldn’t bother if it was going to take longer. You know that. So if you employed a good programmer for a week to crack such a captcha you ought to be able to finish the job off. Then you’d have access to every phpbb3 forum out there.
Clearly there are false positives and things in these processed images: the bottom one in particular has a large false positive in the Z, and the last H has a bit missing where the L overlapped it. I don’t think either of these would actually affect a good OCR algorithm (given that said algorithm would have the font used built into it and have an ideally oriented and scaled image of the letters, albeit with the odd mistake), and even if it did, well, we cracked the other three. If we assume we can crack 75% of these captchas, then we can break into a forum which allows us 5 attempts (which is pretty standard) 99.9% of the time.
phpbb3 also allows the user an almost ludicrous amount of options for their captcha. This is good, as it means that a cracker will have a harder time beating the captcha in the general case. But in the specific case of the default settings, which almost everyone will use, this won’t help at all.
So what’s the solution? Personally, I use a bespoke text-based captcha. Image based ones are hard to programme, which isn’t a problem if you’re doing something like phpbb, because it has to be hard to crack (oh dear) and text based ones really aren’t. Another problem with image-based solutions is that some devices or people can’t read them, so there usually has to be a fallback, and then you have two links, of which a cracker need only outsmart the weakest. (Sorry for the mixed metaphor there.) I think bespoke text-based is good because there’s no really motivation for a cracker to devote any time to cracking it, as they’ll only get access to my websites, and if they do I can very easily change it the following evening. But it couldn’t work for phpbb as you can’t make a bespoke captcha for every user.
Some captchas are obfuscated further than these. Sometimes this is a simple case of drawing lines over and through the text. This is pretty easy to beat – any good photo touching-up software has had this feature since the week after flatbed scanners were invented, and replicating it is not hard, even when the lines must be found automatically. A better solution is to deform the letters themselves, though this involves a very direct tradeoff: anything you do that makes letter shapes harder for a computer to identify will have the same effect for your legitimate users. Again, I would attack such a captcha by not attempting to restore the original image, but by developing an algorithm to characterise each… well, character based on its Euler number, the number of sharp corners in its outline and their relative locations, and maybe the Euler number of the shape you get if you dilate it a bit. I believe this could crack such a captcha with minimal training.
Theoretically, human authentication is the best way, but humans aren’t apparently very good at that. It’s not always apparent from a name and an email address if a user is a human or a spambot. My proposed solution is a deliberately impossible captcha: you find or create an image, possible of random abstract ‘art’, or a landscape, or a sort of randomly generated Rorschach ink-blot test, and ask the user for a vague, one sentence description. Then a human would authenticate the user’s account by seeing if the user’s description of the image relates to that image in any way. It’d be a little subjective, but I really can’t see it being cracked, except perhaps be Derren Brown concocting a sentence that would appear to describe any image. And people would learn to spot that sentence. It would still be susceptible to the porn crack, but then everything is, and honestly I think it’d be fairly easy to tell which descriptions of Rorschach ink-blots had come from the minds of teenage boys looking for naked pictures with a pretty high degree of certainty.
Plus, I think it’d offer a fascinating glimpse into the psyche of all prospective users of your forum.
You can download all the above code, and some general making-it-work gubbins in the Code Factory, but you’ll need Matlab to make it work, and you’ll need the Image Processing Studio, to make it run. If anyone wants to extend the code, do feel free. Complete code is available if you want it, though – people sell it to prospective spammers.